Hualos - 在Keras中動態監視training過程
Keras本身就有提供callbacks機制,可以讓我們在training過程中,看到一些資訊。
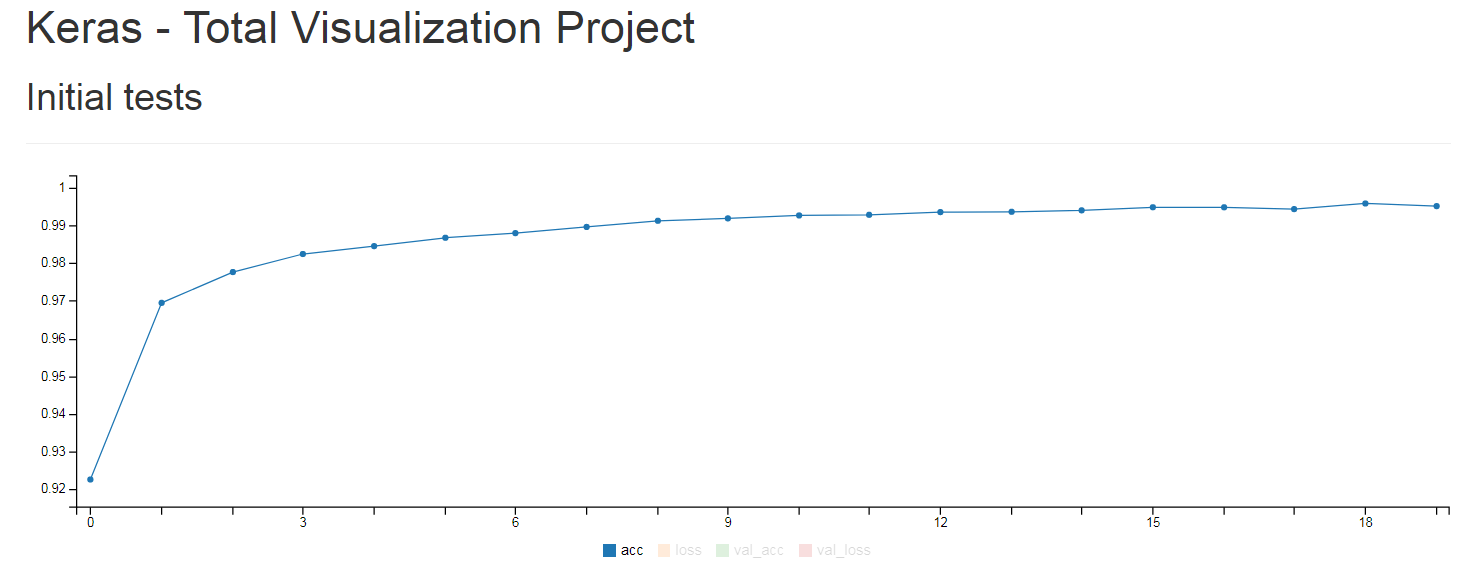
這邊要教如何使用Hualos,讓我們在Web上看到training時的acc、loss等變化。
使用RemoteMonitor
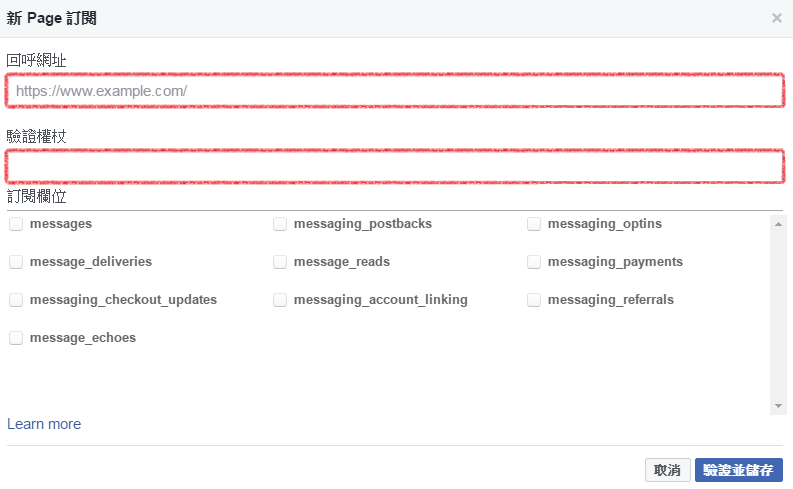
我們可以直接用callbacks.RemoteMonitor()將training時的acc、loss、val_acc、val_loss,POST到我們的Server上。
1 | from keras import callbacks |
當然網頁要自己寫太麻煩了,這邊使用Hualos來替我們完成。
安裝Hualos所需套件
由於Hualos需要用到以下兩個Python套件,可以透過pip直接安裝
- Flask
- gevent
1 | $ pip install flask gevent |
下載Hualos
1 | $ git clone https://github.com/fchollet/hualos.git |
執行Hualos
1 | $ python hualos/api.py |
開啟瀏覽器,進入localhost:9000
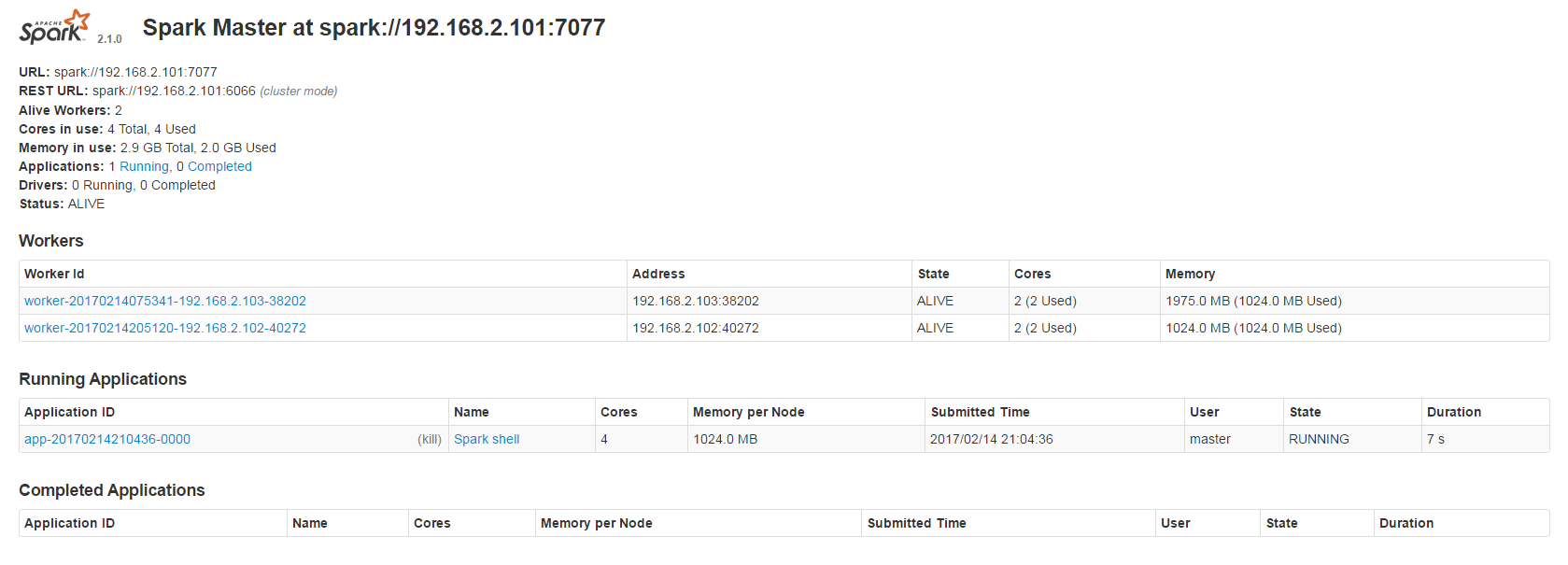
Training
使用mnist為範例,完整程式碼如下
1 | import keras |
回到網頁就能即時看到training時的acc、loss、val_acc、val_loss。